Local Citation Recommendation
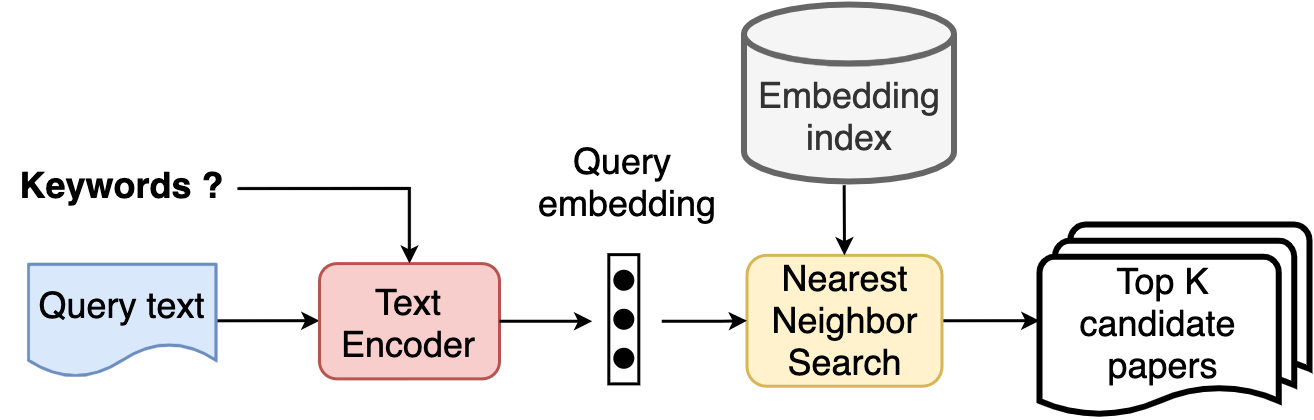
In scientific research and writing, literature discovery is an important task that researchers need to perform when they want to find literature related to a topic or papers that either support or refute a given statement. However, literature discovery is challenging in today's age of information flooding, as there are millions of published scientific papers and their number is rapidly increasing. Local citation recommendation aims to facilitate the literature discovery process by automatically retrieving relevant papers from large-scale databases given a query that is usually a short text such as a claim and that contains no proper references.
Traditionally, literature discovery is performed using probabilistic retrieval frameworks such BM25 and TF-IDF (1). However, such models can neither deal with wording differences or synonyms, nor can they interpret the semantic meaning of a text. Motivated by word embedding models such as Word2Vec, sentence embedding models such as sent2vec and doc2vec have been proposed that compute a document’s embeddings that is then used in the citation recommendation task: Given a query, we first compute its embedding, then we perform nearest neighbour search to obtain related documents whose embeddings are close to the query embedding measured by Euclidean distance or cosine distance. Such an embedding-based ranking system has been proved effective on various text retrieval tasks (2) and they can be adopted for citation recommendation.
Despite the successes of embedding-based recommendation systems, there are still many unexplored questions. For example, apart from the query text, if we know some keywords on the target paper to be cited, to what extent will the recommendation system be able to benefit from such additional information? If this is the case, is it possible to automatically expand the query text when no keywords are provided so that the recommendation system can benefit from the expanded keywords?
Student Project
If you are interested in this project for an MSc Thesis or Semester Project, please get in touch with Jessica Lam
References
- Robertson, S., Zaragoza, H.: The probabilistic relevance framework: BM25 and beyond. Now Publishers Inc (2009)
- Pagliardini, M., Gupta, P., Jaggi, M.: Unsupervised learning of sentence embeddings using compositional n-gram features.